")
")
Das zunehmende Datenvolumen, kurze Auswertungszeiträume und sich verändernde Daten sowie zunehmende Anforderungen zur Nutzung von Daten erhöhen den Bedarf an einer effektiven und effizienten Datenintegration. Es wird in dem Artikel darauf eingegangen, welche Handlungsoptionen zur Datenintegration bestehen und in welchem Kontext sie Verwendung finden. Es wird das Prinzip des Lean Management auf die Datenintegration angewendet und beschrieben, wie der Wert von Daten gesteigert werden kann.
Themen des Artikels:
- Architekturen zur Datenintegration
- Lean Management
- Prinzipien des Lean Management zur Optimierung der Datenintegration
Heutige Anforderungen an Datenintegration
Mit der fortschreitenden Digitalisierung lassen sich heute Informationen in Echtzeit erfassen und weltweit vernetzen. Die exponentiell steigende Informationsflut will gemeistert werden, zumal die Mehrzahl der Informationen in Organisationen Schätzungen zu Folge in unstrukturierter Form vorliegt. Es werden Methoden und Werkzeuge benötigt, mit denen Informationsbedarf identifiziert, Informationsverhalten analysiert und relevante Informationsinhalte erschlossen, strukturiert und integriert werden.
Datenintegration ist ein Teil der Integrationsanstrengungen, IT Infrastrukturen zu öffnen, um andere Ökosysteme von Lieferanten, Kunden, Tech-Start-Ups, autonomen Maschinen und Werkzeuge von Dienstleistungen - auch Konkurrenzsystemen – miteinander zu verbinden. Daten sind Träger dieser Informationen, sie enthalten für sie eigene Darstellungen und werden in Medien gespeichert oder transferiert.
Wissen entsteht durch die Verschmelzung von Informationen aus (heterogener) Daten Quellen mit unterschiedlichen konzeptuellen, kontextuellen und typographischen Darstellungen. Datenintegration ist demnach das methodische Verschmelzen unterschiedlicher Datenquellen, um mehr Nutzen aus den Daten zu generieren. IBM definiert Datenintegration: „ Data Integration is the combination of technical and business processes used to combine data from disparate sources into meaningful and valuable information”.
Die Integration der Daten kann physisch oder virtuell erfolgen. Die hierzu notwendigen Architekturen und technischen Prozesse unterscheiden sich zum Teil grundlegend. Folgende Alternativen werden heutzutage praktiziert:
- Datenkonsolidierung: Daten werden aus unterschiedlichen Quellen zusammengeführt und in einer neuen Version konsolidierter Daten in einem Datenspeicher abgelegt. In Folge können Anwendungen zur Nutzung der konsolidierten Datenspeicher angepasst werden und die Anzahl von Datenspeicher reduziert werden. ETL (extract, transform, load) Technologie unterstützt diese Datenkonsolidierung. ETL Prozesse bereinigen, filtern, transformieren Daten und wenden hierzu Geschäftsregeln an, bevor die konsolidierten Daten in dem neuen Datenspeicher abgelegt werden. Master Data Management kann als eine Strategie betrachtet werden, Stammdaten zu konsolidieren.
- Datenweiterleitung: Anwendungen werden verwendet, Daten zu kopieren und dabei Daten zu übertragen. Diese Übertragung ist ereignisgesteuert und kann synchron- oder asynchron erfolgen. Es sind sehr häufig synchrone Übertragungen zwischen zwei Systemen im Einsatz. Enterprise Application Integration (EAI) und Enterprise Data Replication (EDR) sind Technologien, die eine Weiterleitung von Daten unterstützen. EAI integriert Middleware Komponenten zum Austausch von Meldungen und Transaktionen. EAI kommt in der Regel in Near-Realtime Transaktionsverarbeitungen zum Einsatz. EDR wird in der Regel zur Replikation von großen Datenmengen zwischen Datenbanken eingesetzt. Hier steht dann die Robustheit gegenüber Datenverlust im Vordergrund.
- Datenvirtualisierung: Virtualisierung nutzt Interfaces, um in Realtime Daten aus unterschiedlichen Quellen und unterschiedlichen Datenmodellen bereitzustellen. Daten können an einer Stelle betrachtet werden, aber sind an anderen Orten gespeichert. Datenvirtualisierung erhält Daten und interpretiert Daten, benötigt keine einheitliche Formatierung der Daten oder exklusiver Zugänge auf Daten. Layer Architekturen in Data Warehouses nutzen Virtualisierungen, um mit Business Layern, einer logisch mitunter abweichenden Sichtweise, auf physikalisch repräsentierte Daten zuzugreifen.
- Data Federation: Anwendungen, die es ermöglichen, Daten aus unterschiedlichen Quellen zu sammeln und in einer virtuellen Datenbank zu integrieren, so dass sie anschließend von anderen Anwendungen verwendet werden können. Data Federation ist eine Form der Virtualisierung, bei der die virtuelle Datenbank die Daten nicht beinhaltet. Stattdessen enthält sie Informationen über die tatsächlichen Daten und ihren Speicherort. Die aktuellen Daten verbleiben am Speicherort. Enterprise Information Integration (EII) ist eine Technologie, die Data Federation unterstützt. Sie nutzt Abstraktionen für die Bereitstellung einer einheitlichen Sicht auf Daten unterschiedlicher Quellen. Data Federation erlaubt, Transformationen der virtualisierten Daten auch in den tatsächlichen Datenquellen durchzuführen.
- Data Warehouse: Data Warehouse ist ein Datenspeicher. Daten aus unterschiedlichen Quellen werden in diesem Speicher vorwiegend mit ETL Prozessen integriert. Es handelt sich hierbei in der Regel um eine redundante Datenspeicherung.
Diese Alternativen enthalten unterschiedliche hohe technologische Aufwände und einen unterschiedlichen Betriebs- und Betreuungsumfang. Data Warehouse Ansätze werden in der Regel nicht in operative Anwendungen integriert, sondern dienen Auswertungs-, Analyse- und Planungszwecken sowie der Entscheidungsfindung. Die Datenintegrationsalternativen werden in vielen Situationen auch als Mischformen eingesetzt. Liegen Geschäftsprozesse vor, die mit einer homogenen Anwendungslandschaft abgedeckt werden können, bedarf es keiner aufwendigen Datenintegration wie in heterogenen Anwendungslandschaften. Leider werden Digitalisierungen in der Regel nicht durch ein zentrales ERP-System bestehend aus Standard Anwendungen gelöst. Durch Technologie gestützte (neue) Geschäftsprozesse bedürfen spezialisierter Anwendungen. Es bedarf eines Integrationskonzepts, das effizient und effektiv die Datenintegration zwischen den Standard-Anwendungen und Business-Anwendungen unterstützt. Dabei sind Kosten-, Compliance-, Security-, Agilitäts-, Komplexitäts- oder Performance- oder Verügbarkeits- Kriterien zu optimieren.
Lean Management
Lean-Management ist ein Führungs- und Organisationskonzept zur schlanken, aber gleichzeitig effektiven und effizienten Gestaltung von Aufbau- und Ablauforganisationen. Verantwortlichkeiten und Kommunikationswege sollen logisch gestaltet werden, wobei die zwei bedeutendsten Aspekte des Lean-Management-Ansatzes die Kundenorientierung und die Kostensenkung sind. Diese Schwerpunkte können sich sowohl auf interne als auch auf unternehmensübergreifende Prozesse und Strukturen beziehen.
Hauptziel des Lean-Managements besteht darin, Verschwendung zu minimieren, Überflüssiges auszuschließen und Prozesse derart zu optimieren, dass sie perfekt miteinander harmonieren. Durch Verschlankung können sowohl Kosten als auch Zeit gespart werden, was es dem Unternehmen ermöglicht, weitaus effizienter zu agieren. Der ganze Ansatz findet seine Verankerung hierbei tief in der Produktion und Organisation. Die gesamte Wertschöpfungskette wird dadurch auf eine „just in time“-Effizienz hin optimiert.
Eine weitere Ebene, auf der der Ansatz des Lean-Managements greift, ist das Personal. Die Führungsphilosophie bezieht Mitarbeiter in die Prozesse der Verschlankung mit ein und nutzt so die vorhandenen Kompetenzen. Durch diese Integration in Entscheidung und Verschlankung werden die Mitarbeiter motiviert und das Bewusstsein für Lean-Management kann in allen Bereichen gestärkt werden, sodass ein ganzes Unternehmen im Sinne dieses Ansatzes funktioniert.
Das Lean Management Konzept kann auf Kunden ausgedehnt werden, indem Sie sich auf günstigere Produkte mit zielgruppenspezifischen Eigenschaften freuen können, da auf Unternehmensseite weniger Kosten anfallen und auf überflüssige Produktfeatures verzichtet wird.
Übertragung Lean Management auf Datenintegration
Lean-Management ist ein anerkannter Managementansatz. Datenintegration ist das Management von Technologie sowie technischen und Business-Prozessen, um Nutzen aus der Verschmelzung von Daten unterschiedlicher Quellen zu erzielen. Die Vermeidung von Verschwendung bei der Integration von Daten ist ein Ansatz, Aufwandstreiber zu minimieren und gleichzeitig angestrebtes Wissen durch die Verfügbarkeit von veredelten Daten zu schaffen.
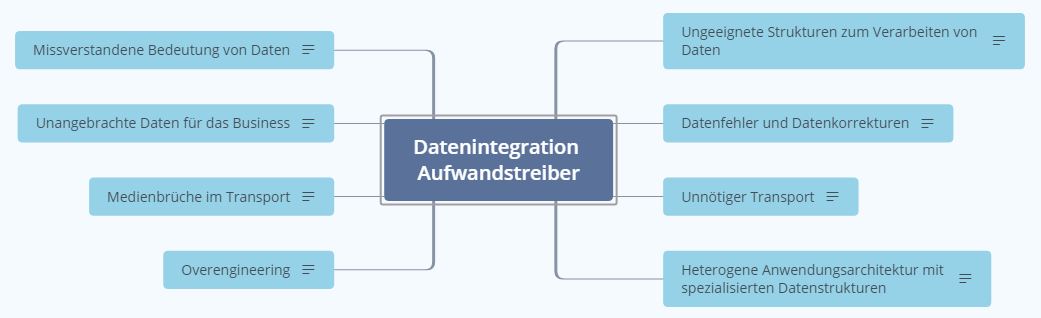 Abbildung 1: Aufwandstreiber Datenintegration
Abbildung 1: Aufwandstreiber Datenintegration
- Missverstandene Bedeutung von Daten: Die Interpretation von Daten erzeugt Informationen die zur Steuerung und Entscheidungsfindung benötigt werden. Unzureichende Kenntnis über die Daten liefert Raum für Spekulationen und Fehlinterpretationen. Sind Daten das Ergebnis analytischer Modelle, muss die Gültigkeit der Modelle gewährleistet sein. Ein unzureichender Knowledge Transfer zwischen Business, Analysten und IT fördert das Missverständnis über die Bedeutung der Daten. Als Folge können falsche Daten als Steuerungsgrößen ausgewählt werden oder Applikationen liefern nicht die angestrebten Daten für das Business. Sind die Relevanz und Eignung als Steuerungsgröße aktuell verfügbarer Daten in Applikationen dem Business nicht bekannt, so stellen sie für das Business keinen Nutzen dar.
- Unangebrachte Daten für das Business: Überflüssige Bereitstellung von Daten, die nicht am Bedarf des Business ausgerichtet sind. Das Business erhält nicht benötigte Daten in zyklisch veröffentlichten Berichten und Dashboards - oftmals aufgrund einmalig angefragter Kennzahlen. Daten enthalten nicht die benötigte Semantik für das Business oder die Aktualität der Daten ist unangemessen. Hierzu zählen auch veraltete Daten oder Datensammlungen in einer Granularität und Häufigkeit, die in keinem Verhältnis zu Ihrer Verwendung stehen. Bei der Erstellung von Schnittstellen werden mehr Daten aus Applikation extrahiert als vom Business benötigt (Überproduktion), da ein zukünftiger Bedarf vermutet, aber nicht verifiziert wird. Daten, die nicht benötigt werden verschwenden Speicherkapazitäten, Backupkapazitäten, Verarbeitungszeit in Bewirtschaftungsjobs, die mit Business Jobs konkurrieren oder binden Ressourcen im Application Management von Schnittstellen bzw. Anwendungen oder für Datenqualitätsanalysen und Datenfehlerbereinigung.
- Medienbrüche im Transport: Inadäquater Einsatz von Ansätzen zur Datenintegration. Geschieht der Transport von Daten über mehrere Schnittstellen, stellt jede Schnittstelle ein Risiko der unkontrollierten Datenveränderung dar. Der kaskadierende Einsatz von Schnittstellen erhöht den Aufwand zur Erstellung und Pflege der Schnittstellen pro Datensatz. Unterschiedliche Technologien und technische Prozesse zum Transport von Daten müssen beherrscht werden (Flow Steuerung, Scheduling, Monitoring, Event Management)
- Overenginieering: Überflüssige, ungenutzte oder nicht angemessene Prozesse, Technologien oder Fähigkeiten. Fehlende Agilität und Freude an der Umsetzung des technisch machbaren, gelebte Bürokratie oder die Verteidigungen von Existenzberechtigungen verschiedener Hierarchieebenen erhöhen die Komplexität und Projektdurchlaufzeiten. Ebenso erhöhen unangemessene und aufwendige Architekturen, falscher Technologieeinsatz, übertriebene Reports, Dokumentationen ohne Nutzen, übertriebene Ausfallsicherheit von Systemen, zu sehr spezialisierte Mitarbeiter die Komplexität der Datenintegration.
- Ungeeignete Strukturen zum Verarbeiten von Daten: Die Aufbau- und Ablauforganisation verfügt nicht über geeignete Kapazitäten oder Wissen/Können, um Integrationslösungen zu erstellen und zu betreiben. Applikation/Infrastruktur Landscape und IT Prozesse sind für Daten Integrationsthemen nicht ausreichend aufeinander abgestimmt, so dass der Datentransfer, Speicherung und Transformation von Daten mit erheblichem korrektivem Aufwand erbracht werden muss. Das Erhalten veralteter Technologie Stacks und Prozesse bindet Ressourcen und erschwert Chancen, Daten Integrationsansätze effektiv und effizient einzusetzen.
- Datenfehler und Datenkorrekturen: Inkonsistente oder nutzlose Daten, angefangen von einfachen Fehlern, verursacht durch Menschen, bis hin zu ungenügenden oder gar nicht vorhandenen unternehmensweiten Datenstandards, die alle Systeme, Geschäftsbereiche und gegebenenfalls Konzerngesellschaften erfassen. Die Datenfehler betreffen Datenquellen als auch die Datenverarbeitung im Rahmen der Daten Integration. Mangelnde Datenstandards, Qualitätsbewusstsein, Ownership für Datenquellen (Sources) und Datenverarbeitung (Anwendungen) führen zu Fehlern, die den Nutzen der Daten reduzieren. Ungeklärte Zuständigkeiten und Abhängigkeiten zwischen Tests von Anwendungen und Datenprüfungen im Rahmen von DQA (Data Quality Assurance) oder Wiederstände zur Korrektur von Fehlern beim Verursacher verzögern die nachhaltige Entfernung von Datenfehlern.
- Unnötiger Transport: Der kaskadierende Transport von Daten ist häufig verbunden mit Medienbrüchen. Mehrstufige Genehmigungsverfahren (mehrere Hierarchieebenen und Hoheitsgebiete), Datenschutz, Security, Compliance Regeln, verschiedene Prüfungen oder Freigaben oder Aufteilungen bei Dokumentationen erschweren den Zugriff auf Daten und deren Integration. Hiervon sind insbesondere Daten-Silos betroffen, die ein Hoheitswissen darstellen können. Widerstände im Austausch von Meta-Wissen über Daten erschwert den Knowledge Transfer.
- Heterogene Anwendungsarchitektur mit spezialisierten Datenstrukturen: Gewachsene Anwendungslandschaften zeichnen sich dadurch aus, dass für ein und denselben Geschäftsprozess häufig mehrere Anwendungen unterschiedlicher Hersteller oder Entwicklerteams im Einsatz sind. Die reine Menge zu integrierender Anwendungen wird damit potentiell erhöht. Individuelle Live-Cycle von Anwendungen, unterschiedliche Schnittstellen, eingeschränkter Datenzugriff und in den Anwendungen verwendete Datenstrukturen erhöhen die Komplexität, Daten von ausgewählten Geschäftsprozessen zu integrieren. Customizing in Anwendungen ist ein weiterer Komplexitätstreiber.
Die aufgeführten Aufwandstreiber sind in der Regel stark voneinander abhängig. Ein Aufwandstreiber kann einen anderen verursachen. So führen missverstandene Bedeutungen von Daten zu unbrauchbaren Daten. Die Korrektur von Datenfehlern schlägt fehl, wenn die Bedeutung der Daten nicht berücksichtig wird. Eine heterogene Anwendungsarchitektur erhöht die Wahrscheinlichkeit der Notwendigkeit des Einsatzes unterschiedlicher Schnittstellentechnologien, die wiederum zu Medienbrüchen im Transport führen.
Es ist wichtig die Aufwandstreiber zu erkennen, um diese zu reduzieren bzw. zu eliminieren. Es muss die Bereitschaft bestehen, etablierte Ansätze und Praktiken in Frage zu stellen. Eine Kultur, Fehler zu erkennen, zu benennen und daraus zu lernen, wird die Verringerung von Verschwendung fördern
Lean Data Integration Prinzipien
Die Basis für Lean Management in der Produktion ist die Einhaltung von fünf Lean-Prinzipien:
- Kundenorientierung. Den Wert des Produktes oder der Leistung aus Sicht des Kunden definieren
- Nutzen/Wertorientierung: Den Wertestrom und Verschwendung ermitteln und eliminieren
- Flussprinzip: Der kontinuierliche Fluss von Material und Information, um damit eine möglichst geringe Durchlaufzeit über die gesamte Wertschöpfungskette zu erreichen; z.B. Fertigung von kleinen Losen sowie Vermeidung von Liegezeiten und Zwischenlagerung.
- Pull-Prinzip: Erst auf Kundenanfrage aktiv werden und die Kapazität bedarfsgerecht austesten. Die Planung und Steuerung erfolgt dabei zentral.
- Null-Fehler-Prinzip: Streben nach Perfektion und ständiger Verbesserung, indem der Status Quo fortwährend von jedem einzelnen Mitarbeiter in Frage gestellt wird.
Einige der Lean-Management Prinzipien lassen sich direkt auf die Datenintegration anwenden. Die Datenintegration kann als Maßnahme verstanden werden, den Rohdaten (Produktionsfaktoren) weiteren Nutzen hinzuzufügen, in der Art und Weise wie Daten zusammengestellt, aufbereitet und dargestellt werden, um Anwendern (Kunde) durch Prozesse des Austauschens, Teilens und Kollaboration die Daten zur Mehrung von Wissen und Können zugänglich zu machen. Der Kunde kann hierbei intern als auch extern sein. Alle Ergebnisse und Aktivitäten müssen kritisch im Hinblick auf den Kundennutzen geprüft werden. Die Architektur und technischen Prozesse müssen sich an den Kundenanforderungen zur Datenintegration ausrichten. Die Datenauswahl und Integration muss am Kunden ausgerichtet sein (als Teil des Service Portfolio). Die Kundenanforderungen müssen verstanden werden und angemessene Lösungen sind im Dialog mit dem Kunden zu gestalten, zu planen und umzusetzen. Zwischenergebnisse sollten einen Wert für den Kunden darstellen.
Das Lean-Management greift hier weiter als ein Lean Data Integration. Im Fall der Datenintegration sind unnötige Aufwandstreiber zu eliminieren. Zu den Aufwandstreibern zählen die missverstandene Bedeutung von Daten, unangebrachte Daten für das Business, Medienbrüche im Transport, Overenginieering, uneeignete Strukturen zum Verarbeiten von Daten, Datenfehler und Datenkorrekturen, unnötiger Transport oder heterogene Anwendungsarchitektur mit spezialisierten Datenstrukturen. Dies beinhaltet auch kontinuierliche Aktivitäten, unnötige Daten, Technologien, Prozesse und Rollen/Funktionen zu eliminieren. Mängel im Fluss der Informationen können anhand von Medienbrüchen im Transport und dem unnötigen Transport aufgedeckt werden. Organisations-, Technologie und Prozessbrüche werden über Störungen im kontinuierlichen Fluss der Daten deutlich. Identifizierte Datenfehler und Schwächen in der Fehlerkorrektur stören den Datenfluss. Wartezeiten von der Identifikation notwendiger Daten bis zu deren Bereitstellung müssen optimiert werden, indem wieder verwendbare Technologiekomponenten, agile Entwicklungsmethoden, Self-Service Liefermodelle sowie reife Service Management Prozesse angewendet werden.
Die IT Organisation muss für die Datenintegration ausgelegt sein, indem eindeutige Rollen für die Verantwortung von Infrastruktur- und Organisationsstrukturen, Operation Modell (zumeist Chief Information Officer), Gestaltung eines Technologie- und Sourcing Stracks (zumeist Chief Technologie Officer), Wertschöpfung von IT Prozessen im Business mit unterschiedlichen Online-Kanälen, Monetarisierung von E-Commerce-Modellen (zumeist Chief Digital Officer) sowie Datenmanagementstrategie, Data Governance, Datenarchitektur, Datenqualität, Master Data Management, Data Science und Business Analytics (zum Teil Chief Data Officer) definiert, bekannt und von Führungskräften übernommen werden. Mitarbeiter müssen ihre Rollen genau kennen und Verständnis und Wissen über andere Rollen aufweisen. Um systematisch den Lean Prinzipien zu folgen, müssen klassische Management Controls überarbeitet werden. Rollen sollten in schlanken Hierarchien, dezentralisiert und mit einem hohen Maß and Eigenverantwortung abgebildet werden. Es ist der Nutzen der Datenintegration anhand von KPIs und Benchmarks zu messen. Diese Zielgrößen treiben die kontinuierliche Verbesserung der IT Organisation, Prozesse, die Technologieverwendung und Datenkataloge (als Teil des Service Portfolio). Diese Verbesserungen führen zu klaren Rollenbildern, stabilen und überschaubaren sowie beherrschbaren Prozessen, die fehlerarme und aussagefähige Daten zur Verfügung stellen.
Die Notwendigkeit zur Einhaltung des Pull-Prinzips wird nicht immer gegeben sein. Zur Reduktion von Verschwendung sollten nur die Daten integriert werden, für die auch ein Business-Nutzen besteht. Im Zuge der Digitalisierung sind jedoch datengetriebene Angebote zu verifizieren. Die Entwicklung solcher Angebote muss agil erfolgen, um kurzfristig den Nutzen prüfen zu können und Entscheidungen über die Fortführung und den Ausbau solcher Angebote herbeizuführen. Die Anpassung der Organisation, Prozesse, Leistungsportfolio, Technologie- und Sourcing Stacks unterliegen strategischen Entscheidungen, die nicht immer auf Basis von Kundenanfragen oder Kapazitätsplanungen getroffen werden.
Beim Streben nach Perfektion wird jeder Fehler als Störung des Prozesses angesehen. Deshalb gehen Verantwortliche dem Problem vor Ort und sofort auf den Grund. Data Quality Assurance wird kontinuierlich ausgebaut. Test zur Prüfung der Datenqualität und Datenverarbeitungsqualität werden kontinuierlich angepasst und ggf. automatisiert. Unternehmensweite Datenstandards werden kontinuierlich optimiert und an die Businessmodelle angepasst. Die Folge ist ein Effizienz- und Qualitätsgewinn durch die Reduktion von Datenfehlern. Entscheidungsvorlagen und Berichte beruhen auf Daten hoher Qualität. Mit dem Erkennen und Beseitigen von Fehlern geht ein Lernprozess und ein umfassendes Zusammenarbeitsmodell der Organisation einher (lernende Organisation). Die Integration der Fachbereiche in die Lösung (kritischer) Situationen eliminiert die Akkumulation von (Qualitäts-)Problemen gegenüber der ausschließlichen Lösung durch IT Mitarbeiter. Der LifeCycle von Anwendungen und Schnittstellen wird hinsichtlich ihrer Robustheit, Betreuungsintensität und des Wertbeitrags kontinuierlich adjustiert. Standardisierungen von Anwendungen und Schnittstellen mit agilen Entwicklungsmethoden unterstützen die Fehlervermeidung und die Reduktion von Kopfmonopolen. Werden kontinuierliches Build und Deployment von Anwendungen erforderlich, so können Continuous Integration (CI) beziehungsweise Continuous Deployment (CD) für Entwicklungs-, Test- und Produktionsumgebungen etabliert werden. Beim Streben nach Perfektion ist es wichtig, Fehler zu machen. Durch Selbstreflektion und Abstellen der Fehlerursachen lernen die Beteiligten, gleichartige Fehler zu vermeiden. Es ist wichtig, dass Fehler zu Tage treten und nicht verschwiegen werden. Lean Data Integration unterstützt damit DevOps. Das Streben nach Perfektion greift nicht nur bei der Fehlervermeidung, sondern dient dem Erproben neuer Möglichkeiten der Wertschöpfung aus Daten oder dem Austesten geänderter Schnittstellen und Applikationen zur Wertsteigerung.
Fazit
Lean Data Integration Prinzipien sind in der Lage, Kosten-, Agilitäts-, oder Komplexitätskriterien bei Lösungen zur Datenintegration zu optimieren. Auch Compliance-, Security-, Performance- und Verfügbarkeits- Kriterien liefern einen Kundennutzen und Wertbeitrag und sollten daher mit Lean Data Integration Prinzipien zu optimieren sein. Die Bereitstellung von Daten, Prozessen, Menschen und Technologie rein auf der Basis von Kundenanfragen und Kapazitätsanforderungen reicht nicht aus, sondern unterliegt auch strategischen Entscheidungen und Planungen. Ein effizientes Changemanagement zur Umsetzung von Kundenanforderungen mit minimaler Wartezeit ist sehr wichtig.
Datenqualität ist ein entscheidender Faktor einer erfolgreichen Datenintegration. Der Wert der Daten wächst, wenn das Vertrauen in die Vollständigkeit, Eindeutigkeit, Korrektheit, Aktualität, Genauigkeit, Konsistenz, Redundanzfreiheit, Relevanz, Einheitlichkeit und Zuverlässigkeit der Daten gewährleistet ist. Daten müssen als ein Asset betrachtet werden, mit einer planvollen Entstehung, Verwendung und Qualitätssicherung. Die Wertentwicklung hängt von der Verantwortungsübernahme von Führungskräften und Mitarbeitern ab, Datenqualität nachhaltig zu verbessern. Die kontinuierliche Pflege einer Knowledge Base über sämtliche Daten-Assets liefert einen Beitrag der Wertsteigerung von Daten.
Der Erfolg dieser Prinzipien wird nicht getragen durch eine Konsolidierung der Datenintegrationstechnologie oder dem Einsatz (moderner) Datenmanagement-Werkzeuge, die eine flexible Cloudintegration und agile Software-Entwicklungen versprechen. Einen wesentlichen Beitrag leistet das „Lean Mindset“, dass eine spezifische Organisations- und Führungskultur beinhaltet. Mitarbeiter liefern ihre Arbeitsergebnisse nicht auf der Basis klarer Vorgaben, sondern durch Übernahme von Verantwortung für ihre Arbeitsergebnisse: Klare Verantwortung statt genauer Vorgaben. Das Verständnis für die Sinnhaftigkeit von Regeln, Standards und Bereitschaft diese zu optimieren, sowie Fehler zu kommunizieren und daraus zu lernen sind wichtige Elemente. Im Mittelpunkt steht der Mitarbeiter mit seinem Können und Wissen, da darauf die Lösungskompetenz und Prozessbeherrschung basiert. Lean Dataintegration ist ein ganzheitlicher Ansatz im Sinne einer Kultur. Das Verhalten beim Anwenden von Methoden ist dabei wichtiger als die Methode an sich. Dezentrale Kommunikation und ein funktionierender Knowledge Transfer sind bedeutsam. Zentrale Steuerungsgrößen einer solchen Datenintegrationskultur sind der Ausbau des Wertes von Daten, (minimale) Wartezeiten zur Lieferung neuer Daten an Kunden, Förderung von Datenstandards, soziale Kenngrößen zum kollektiven Lernen und Problemlösung. Das Engagement und die Motivation der Mitarbeiter ist durch den Einsatz funktionsübergreifender Zusammenarbeit (One-Piece-Flow) zu erhöhen, um die Wertschöpfung der Datenintegration zu erhöhen. Teams sollten motiviert werden, neue Ideen und Verbesserungen im Datenmanagement planvoll auszuprobieren und wiederkehrende (Routine-)Tätigkeiten zu automatisieren, um vermehrt Zeit für die Bereitstellung (neuer) Daten und die Konsolidierung nicht mehr benötigter Daten zu haben. Die Verwendung automatisierter Datenmanagement Prozesse, wiederverwendbare Anwendungen und Schnittstellen und Self-Service Delivery Modelle tragen zur Vermeidung kritischer Pfade in Projekten bei, die auf (existierende) Datenintegrationen angewiesen sind.